






节能企业信用风险识别体系及步骤解析
2014-05-21 00:07
蓝林笑生
关注
(二)数据补全与属性离散化
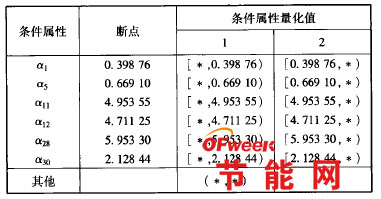
选取的120组数据中多数信息完整,少数信息不完整。为了保证结果的准确性,补全不完整信息使用的是Mean/Mode6u。将Utrain中120个样本的属性值和决策值输入Excel中,对不同算法的离散化结果进行比较。为使结果简洁方便,离散化使用粗糙集理论结合布尔逻辑的算法,求得6个属性的6个断点(见表2)。依据属性赋值与断点可以确定新的决策表。
表2 条件属性量化参数
(三)决策表属性约简
将决策表输入Rosetta软件进行属性约简。由于算法ManualReducer和Holte’S包含30个属性,算法Johnson’sAlgorithm与GeneticAlgorithm的约简数量分别是17个、11个,为体现属性约简的便利性,选择Ge—neticAlgorithm的约简结果(见表3)。
表3 GeneticAlgorithm生成的可能约简

(四)确定决策规则
根据表3的约简结果和最小决策原则,使用Ge.neticAlgorithm确定决策规则(见表4)。
表4 基于粗糙集理论的信用风险识别决策规则

(五)决策规则检验
依据信用风险识别中的检验原则检验上述决策规则。原始数据选用5个上市公司的财务指标,离散化结果赋值选用表3中数据,判断依据是上述决策规则。通过与已知信用状况的对比,显示5组指标符合预测情况(见表5),证实对节能企业信用评价可以使用基于粗糙集理论的信用评价模型。

 分享
分享
声明:
本文由入驻维科号的作者撰写,观点仅代表作者本人,不代表OFweek立场。如有侵权或其他问题,请联系举报。















发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论